为了加快文档编写速度,我们加快描述。 首先是RMSNorm的实现。我们这里的实现是遍历Embedding_batch中的每个Embedding的Token,对其做RMSNorm的操作:
embedding_batch RMSNorm(const embedding_batch &token_embedding, float eps) {
if (token_embedding.hidden_size == 0) {
throw std::runtime_error("hidden size must be greater than zero");
}
embedding_batch result{};
result.token_count = token_embedding.token_count;
result.hidden_size = token_embedding.hidden_size;
result.values.resize(token_embedding.values.size());
for (uint32_t token_index = 0; token_index < token_embedding.token_count; ++token_index) {
const size_t begin = static_cast<size_t>(token_index) * token_embedding.hidden_size;
const size_t end = begin + token_embedding.hidden_size;
float sum_of_squares = 0.0f;
for (size_t i = begin; i < end; ++i) {
sum_of_squares += token_embedding.values[i] * token_embedding.values[i];
}
const float mean_of_squares = sum_of_squares / static_cast<float>(token_embedding.hidden_size);
const float inv_rms = 1.0f / std::sqrt(mean_of_squares + eps);
for (size_t i = begin; i < end; ++i) {
result.values[i] = token_embedding.values[i] * inv_rms;
}
}
return result;
}在实际的Transformer计算中,我将模型每一层的完全计算放到了一个block里,具体的执行逻辑在run_block中:
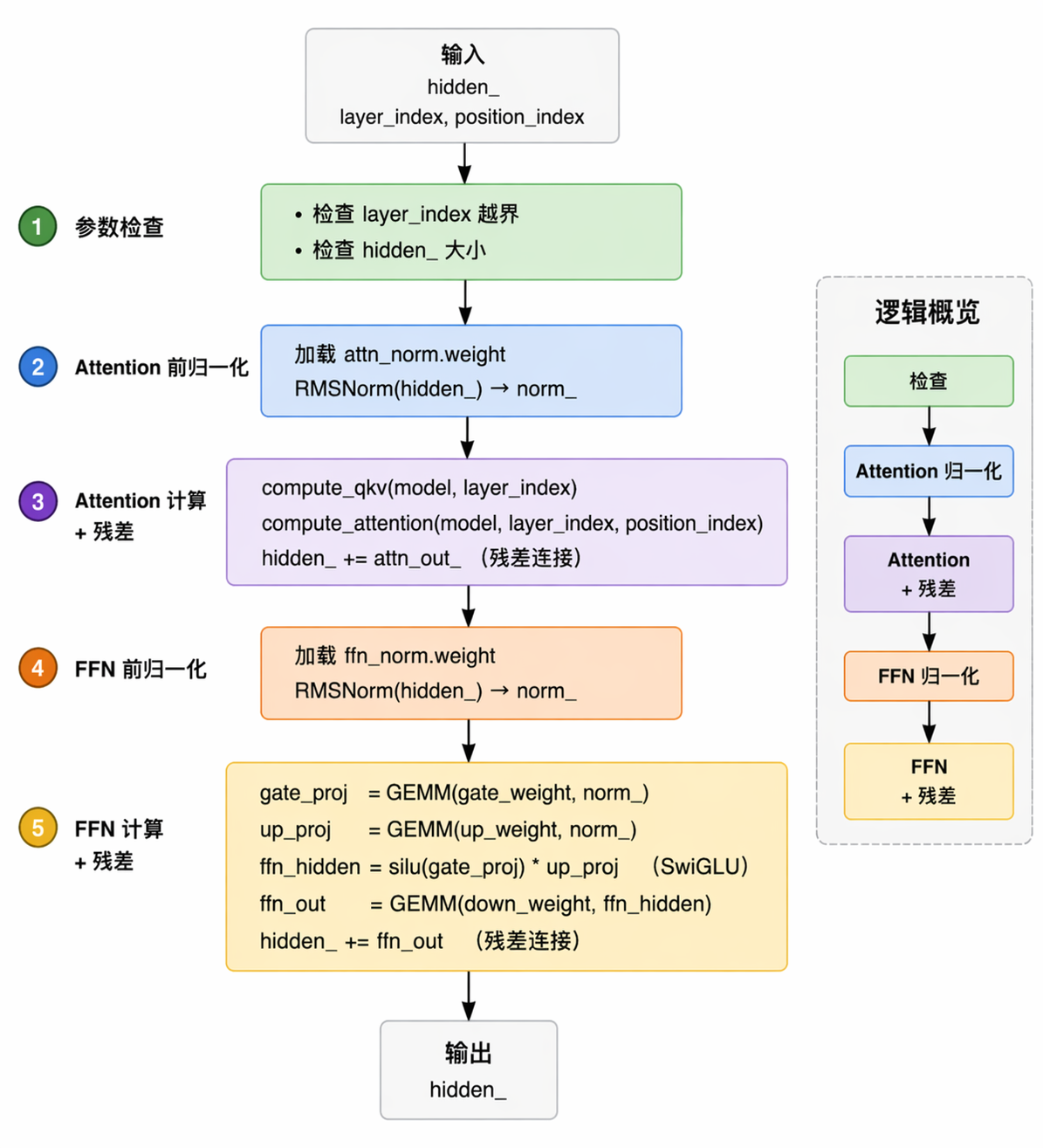
void run_state::run_block(const gguf_model &model, uint32_t layer_index, uint32_t position_index) {
if (layer_index >= shape_.n_layers) {
throw std::out_of_range("layer index out of range");
}
if (hidden_.size() != hidden_elements()) {
throw std::runtime_error("hidden buffer size mismatch");
}
const std::string prefix = "blk." + std::to_string(layer_index);
constexpr float kRmsNormEps = 1e-6f;
const std::string attn_norm_weight_name = prefix + ".attn_norm.weight";
const gguf_tensor_data &attn_norm_weight_tensor =
load_gguf_tensor_data(model, attn_norm_weight_name);
const std::vector<float> attn_norm_weight = read_tensor_vector(attn_norm_weight_tensor);
weighted_rmsnorm_batch(
hidden_,
shape_.batch_size,
shape_.hidden_size,
attn_norm_weight,
kRmsNormEps,
norm_
);
compute_qkv(model, layer_index);
compute_attention(model, layer_index, position_index);
for (size_t i = 0; i < hidden_.size(); ++i) {
hidden_[i] += attn_out_[i];
}
const std::string ffn_norm_weight_name = prefix + ".ffn_norm.weight";
const gguf_tensor_data &ffn_norm_weight_tensor =
load_gguf_tensor_data(model, ffn_norm_weight_name);
const std::vector<float> ffn_norm_weight = read_tensor_vector(ffn_norm_weight_tensor);
weighted_rmsnorm_batch(
hidden_,
shape_.batch_size,
shape_.hidden_size,
ffn_norm_weight,
kRmsNormEps,
norm_
);
const std::string gate_weight_name = prefix + ".ffn_gate.weight";
const std::string up_weight_name = prefix + ".ffn_up.weight";
const std::string down_weight_name = prefix + ".ffn_down.weight";
const gguf_tensor_data &gate_weight = load_gguf_tensor_data(model, gate_weight_name);
const gguf_tensor_data &up_weight = load_gguf_tensor_data(model, up_weight_name);
const gguf_tensor_data &down_weight = load_gguf_tensor_data(model, down_weight_name);
std::vector<float> gate_proj;
std::vector<float> up_proj;
gemm_batch(
gate_weight,
norm_,
shape_.batch_size,
shape_.hidden_size,
shape_.ffn_hidden_size,
gate_proj
);
gemm_batch(
up_weight,
norm_,
shape_.batch_size,
shape_.hidden_size,
shape_.ffn_hidden_size,
up_proj
);
std::vector<float> ffn_hidden(gate_proj.size(), 0.0f);
for (size_t i = 0; i < ffn_hidden.size(); ++i) {
ffn_hidden[i] = silu(gate_proj[i]) * up_proj[i];
}
std::vector<float> ffn_out;
gemm_batch(
down_weight,
ffn_hidden,
shape_.batch_size,
shape_.ffn_hidden_size,
shape_.hidden_size,
ffn_out
);
for (size_t i = 0; i < hidden_.size(); ++i) {
hidden_[i] += ffn_out[i];
}
}这里的代码忽略掉一些基本检查,我们可以简单总结出一个Block的计算内容:
在这里我们暂时不对其他的逻辑做出太多陈述,主要查看核心的GEMM:
void gemm_batch(
const gguf_tensor_data &weight,
const std::vector<float> &input,
uint32_t batch_size,
uint32_t input_dim,
uint32_t output_dim,
std::vector<float> &output,
const std::vector<float> *bias = nullptr
) {
if (weight.info.dimensions.size() != 2) {
throw std::runtime_error("projection weight must be 2D");
}
if (weight.info.dimensions[0] != input_dim) {
throw std::runtime_error("projection input dimension mismatch");
}
if (weight.info.dimensions[1] != output_dim) {
throw std::runtime_error("projection output dimension mismatch");
}
if (input.size() != static_cast<size_t>(batch_size) * input_dim) {
throw std::runtime_error("projection input buffer size mismatch");
}
if (bias != nullptr && bias->size() != output_dim) {
throw std::runtime_error("projection bias size mismatch");
}
output.assign(static_cast<size_t>(batch_size) * output_dim, 0.0f);
switch (weight.info.type) {
case GGML_TYPE_F32: {
const float *weight_data = reinterpret_cast<const float *>(weight.raw_data.data());
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (uint32_t out_index = 0; out_index < output_dim; ++out_index) {
const float *row_data = weight_data + static_cast<size_t>(out_index) * input_dim;
for (uint32_t batch_index = 0; batch_index < batch_size; ++batch_index) {
const size_t input_offset = static_cast<size_t>(batch_index) * input_dim;
const size_t output_offset = static_cast<size_t>(batch_index) * output_dim;
float sum = bias == nullptr ? 0.0f : (*bias)[out_index];
sum += dot_product_f32_row(row_data, input.data() + input_offset, input_dim);
output[output_offset + out_index] = sum;
}
}
return;
}
case GGML_TYPE_F16: {
const uint16_t *weight_data = reinterpret_cast<const uint16_t *>(weight.raw_data.data());
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (uint32_t out_index = 0; out_index < output_dim; ++out_index) {
const uint16_t *row_data = weight_data + static_cast<size_t>(out_index) * input_dim;
for (uint32_t batch_index = 0; batch_index < batch_size; ++batch_index) {
const size_t input_offset = static_cast<size_t>(batch_index) * input_dim;
const size_t output_offset = static_cast<size_t>(batch_index) * output_dim;
float sum = bias == nullptr ? 0.0f : (*bias)[out_index];
sum += dot_product_f16_row(row_data, input.data() + input_offset, input_dim);
output[output_offset + out_index] = sum;
}
}
return;
}
default:
throw std::runtime_error("unsupported tensor type");
}
}在这里我们使用了openmp来并行加速推理过程。可以看到计算的最小粒度是下面的矩阵乘(fp16)
for (uint32_t out_index = 0; out_index < output_dim; ++out_index) {
const uint16_t *row_data = weight_data + static_cast<size_t>(out_index) * input_dim;
for (uint32_t batch_index = 0; batch_index < batch_size; ++batch_index) {
const size_t input_offset = static_cast<size_t>(batch_index) * input_dim;
const size_t output_offset = static_cast<size_t>(batch_index) * output_dim;
float sum = bias == nullptr ? 0.0f : (*bias)[out_index];
sum += dot_product_f16_row(row_data, input.data() + input_offset, input_dim);
output[output_offset + out_index] = sum;
}
}dot点积的实现如下:
float dot_product_f32_row(
const float *row_data,
const float *input_data,
uint32_t input_dim
) {
float sum = 0.0f;
for (uint32_t in_index = 0; in_index < input_dim; ++in_index) {
sum += input_data[in_index] * row_data[in_index];
}
return sum;
}这里目前就是我们最需要解决的性能瓶颈,对于这样一个小模型,主要的性能卡点就在于这里的GEMM矩阵乘,这也是之后我们之后CUDA第一步替换的地方。
除此之外,我们整个项目的RunState是通过一个Class来做的,kv-cache使用vector<float>来做。
这样,我们就完成了一个最简单的推理引擎。