从头开始手写一个Qwen的Naive CUDA Kernel推理引擎(一)
在上学期的课程中,我们的任务是对修改后的llama2.c项目(移除了kv-cache和编译器优化)进行优化。因为这个项目强制按组分配,所以我没有机会完整的从头来编写并优化LLM的推理引擎。因此在这里尝试手动从头使用CPU,Naive CUDA Kernel,写一个Qwen的推理引擎。
在这里我们首先选取Qwen2.5-1.5B模型,因为对于Qwen2.5推理引擎来说,这是一个标准的decoder-only Transformer。而Qwen3.5则是Hybrid架构,这个我们将在之后处理。
LLM推理引擎结构
+----------------------------------------------------------------------------------+
| Qwen2.5-1.5B-Instruct.gguf |
+----------------------------------------------------------------------------------+
| Header |
| - magic/version |
| - tensor_count |
| - metadata_kv_count |
+----------------------------------------------------------------------------------+
| Metadata KV |
| - general.architecture = qwen2 |
| - general.name |
| - qwen2.block_count = 28 |
| - qwen2.embedding_length |
| - qwen2.attention.head_count = 12 |
| - qwen2.attention.head_count_kv = 2 |
| - qwen2.rope.freq_base |
| - qwen2.context_length = 32768 |
| - tokenizer.ggml.tokens |
| - tokenizer.ggml.merges / special tokens |
| - general.file_type / quantization info |
+----------------------------------------------------------------------------------+
| Tensor Directory |
| - tensor name |
| - n_dims |
| - shape[] |
| - ggml_type |
| - data_offset |
+----------------------------------------------------------------------------------+
| Tensor Data |
| - token_embd.weight |
| - blk.0.attn_norm.weight |
| - blk.0.attn_q.bias / weight |
| - blk.0.attn_k.bias / weight |
| - blk.0.attn_v.bias / weight |
| - blk.0.attn_output.weight |
| - blk.0.ffn_norm.weight |
| - blk.0.ffn_gate.weight |
| - blk.0.ffn_up.weight |
| - blk.0.ffn_down.weight |
| - ... |
| - blk.27.* |
| - output_norm.weight |
| - output.weight (或 tied 到 embedding) |
+----------------------------------------------------------------------------------+
Qwen2.5模型的gguf格式的内容结构。而要运行这个模型的推理,下面的基本逻辑图是如下的样子:
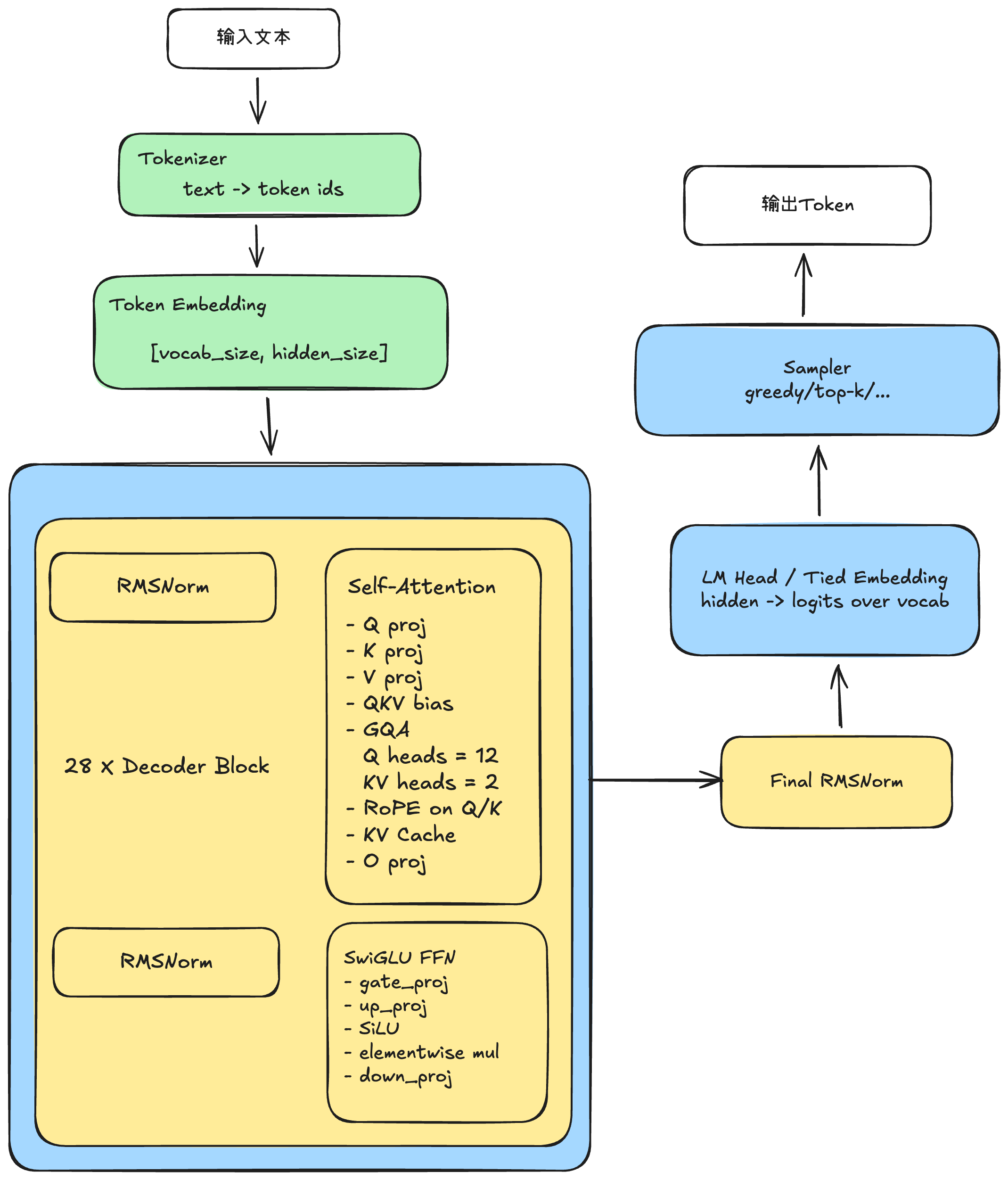
在这里我不做完整的Transformer每个步骤的详解,只做部分的过程解析:
RMSNorm
RMSNorm 是在网络前向传播中对 hidden state 做尺度归一化,以保证深层 Transformer 在训练和推理时的数值稳定。公式如下
简单来说,就是用均方根归一化 hidden state 的尺度。
Rope
Rotary Position Embedding, 旋转位置编码
大模型在讲token转化为高维向量之后,会有一个问题,那就是乱序盲,在它眼里,一个句子你将词语随机打乱生成一个乱序的语句,那么新的语句和之前的语句实际上Token是完全一致的。为了赋予大模型时序感,我们引入Rope.
位置信息本质上是Q和K之间的一种距离关系,而不是V自带的属性。Rope通过绝对位置编码来实现相对位置编码。具体来说就是将位置编码表示为二维空间中的旋转操作。这一变换保留了原始向量的性质,但通过旋转引入了位置信息。如果一个二维向量旋转了 m 弧度,另一个旋转了 n 弧度,那么这两个向量之间的夹角就是 |m - n|。基于这样的思想,我们可以有效地引入相对位置的信息。
SwiGLU
门控神经网络激活结构,
用来替代普通的激活函数。
Sampler
决定怎么选,如Greedy(选择最大),Top-K(在概率最大的k个token中随机采样)
Metadata读取
首先我们要获取到gguf的模型metadata信息,这里我们可以参考huggingsface上能够看到的metadata信息:
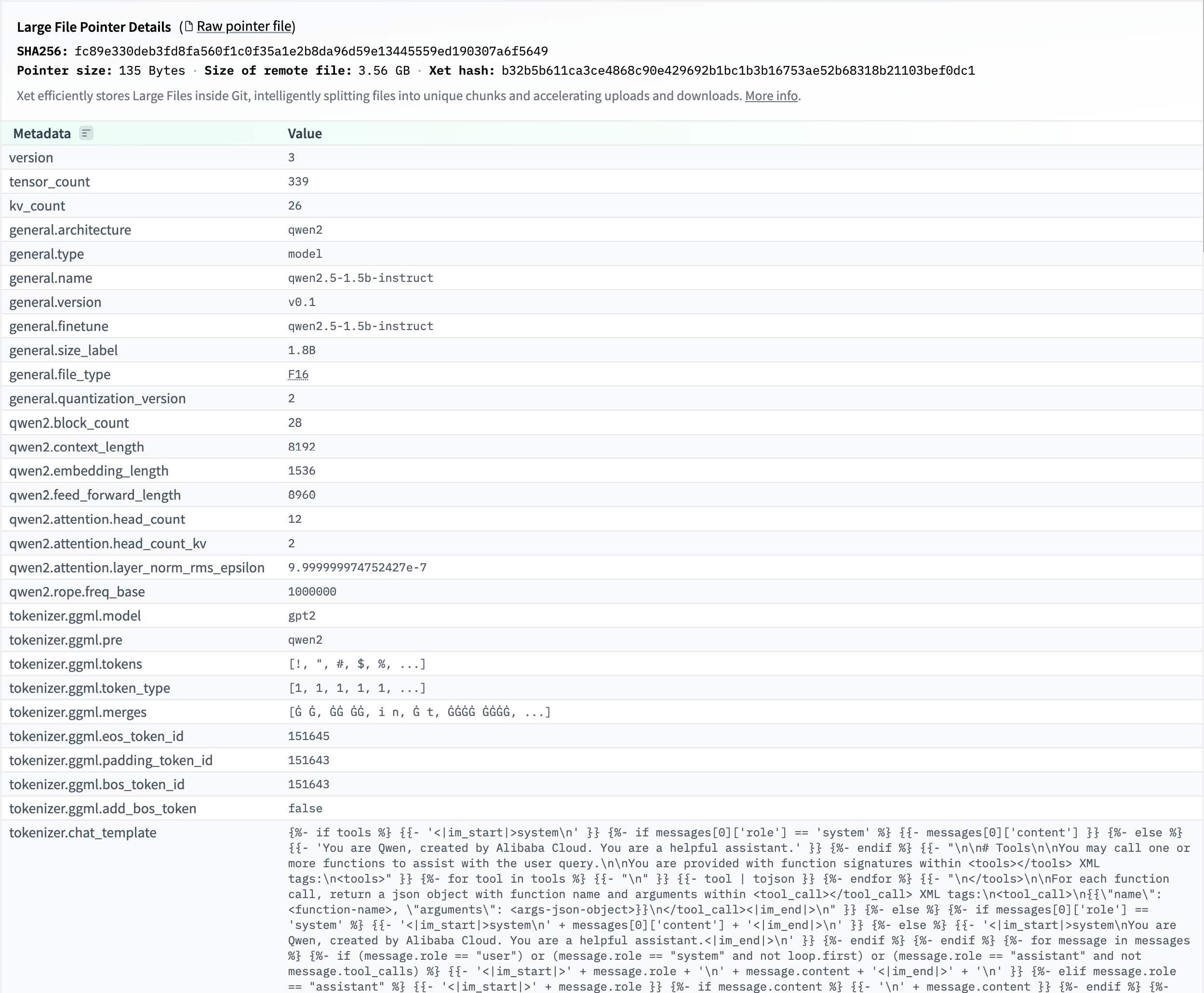
在这里,我们可以将metadata拆为两个部分,header和metadata_kv,其中header包含一个GGUF_Magic(用来标识这个是gguf),还有version, tensor_count, kv_count;而剩下的general, qwen2,tokenizer我们放到一个kv vector中。
首先我们设计一下这里的结构体:
enum gguf_type {
GGUF_TYPE_UINT8 = 0,
GGUF_TYPE_INT8 = 1,
GGUF_TYPE_UINT16 = 2,
GGUF_TYPE_INT16 = 3,
GGUF_TYPE_UINT32 = 4,
GGUF_TYPE_INT32 = 5,
GGUF_TYPE_FLOAT32 = 6,
GGUF_TYPE_BOOL = 7,
GGUF_TYPE_STRING = 8,
GGUF_TYPE_ARRAY = 9,
GGUF_TYPE_UINT64 = 10,
GGUF_TYPE_INT64 = 11,
GGUF_TYPE_FLOAT64 = 12,
GGUF_TYPE_COUNT,
};
struct gguf_header {
uint32_t magic;
uint32_t version;
uint64_t tensor_count;
uint64_t metadata_kv_count;
};
struct gguf_metadata_value {
gguf_type type = GGUF_TYPE_COUNT;
gguf_metadata_payload data{};
};
struct gguf_metadata_array {
gguf_type element_type = GGUF_TYPE_COUNT;
uint64_t len = 0;
std::vector<gguf_metadata_value> values;
};
struct gguf_metadata_kv {
gguf_string key;
gguf_metadata_value value;
};
struct gguf_metadata {
gguf_header header;
std::vector<gguf_metadata_kv> kvs;
};
这里的我们将用kvs的vector来存储相应的数据,而类型中,我们单独处理一下array这个类型,总体使用metadata_value来作为整体kv中的value数值。
下面是对应的函数方法:
gguf_string read_gguf_string(std::ifstream &input);
gguf_metadata_value read_gguf_metadata_value(std::ifstream &input);
gguf_metadata_kv read_gguf_metadata_kv(std::ifstream &input);
gguf_metadata load_gguf_metadata(const std::string & path);
void print_gguf_metadata(const gguf_metadata &meta);
const char * gguf_type_name(gguf_type type);下面是对应的实现:
gguf_string read_gguf_string(std::ifstream &input) {
gguf_string value{};
value.len = read_u64(input);
value.data.resize(checked_size(value.len, "gguf string length"));
if (!value.data.empty()) {
input.read(value.data.data(), static_cast<std::streamsize>(value.data.size()));
if (!input) {
throw std::runtime_error("failed to read gguf string payload");
}
}
return value;
}
gguf_metadata_value read_gguf_metadata_value(std::ifstream &input) {
return read_gguf_metadata_value_of_type(input, read_gguf_type(input));
}
gguf_metadata_kv read_gguf_metadata_kv(std::ifstream &input) {
gguf_metadata_kv kv{};
kv.key = read_gguf_string(input);
kv.value = read_gguf_metadata_value(input);
return kv;
}
gguf_metadata load_gguf_metadata(const std::string &path) {
std::ifstream input(path, std::ios::binary);
if (!input.is_open()) {
throw std::runtime_error("failed to open GGUF file: " + path);
}
gguf_metadata meta{};
meta.header.magic = read_u32(input);
meta.header.version = read_u32(input);
meta.header.tensor_count = read_u64(input);
meta.header.metadata_kv_count = read_u64(input);
if (meta.header.magic != kGgufMagic) {
throw std::runtime_error("invalid GGUF magic");
}
meta.kvs.reserve(checked_size(meta.header.metadata_kv_count, "metadata kv count"));
for (uint64_t i = 0; i < meta.header.metadata_kv_count; ++i) {
meta.kvs.push_back(read_gguf_metadata_kv(input));
}
return meta;
}
void print_gguf_metadata(const gguf_metadata &meta) {
const gguf_header &header = meta.header;
const char magic_text[5] = {
static_cast<char>(header.magic & 0xFF),
static_cast<char>((header.magic >> 8) & 0xFF),
static_cast<char>((header.magic >> 16) & 0xFF),
static_cast<char>((header.magic >> 24) & 0xFF),
'\0'
};
std::cout << "[header]" << '\n';
std::cout << "magic: 0x"
<< std::hex << std::uppercase << header.magic
<< std::dec << " (" << magic_text << ")" << '\n';
std::cout << "version: " << header.version << '\n';
std::cout << "tensor_count: " << header.tensor_count << '\n';
std::cout << "metadata_kv_count: " << header.metadata_kv_count << '\n';
std::cout << "[metadata]" << '\n';
for (auto it = meta.kvs.cbegin(); it != meta.kvs.cend(); ++it) {
std::cout << it->key.data << ": ";
print_gguf_metadata_value(std::cout, it->value);
std::cout << '\n';
}
}
const char *gguf_type_name(gguf_type type) {
switch (type) {
case GGUF_TYPE_UINT8:
return "UINT8";
case GGUF_TYPE_INT8:
return "INT8";
case GGUF_TYPE_UINT16:
return "UINT16";
case GGUF_TYPE_INT16:
return "INT16";
case GGUF_TYPE_UINT32:
return "UINT32";
case GGUF_TYPE_INT32:
return "INT32";
case GGUF_TYPE_FLOAT32:
return "FLOAT32";
case GGUF_TYPE_BOOL:
return "BOOL";
case GGUF_TYPE_STRING:
return "STRING";
case GGUF_TYPE_ARRAY:
return "ARRAY";
case GGUF_TYPE_UINT64:
return "UINT64";
case GGUF_TYPE_INT64:
return "INT64";
case GGUF_TYPE_FLOAT64:
return "FLOAT64";
case GGUF_TYPE_COUNT:
return "COUNT";
default:
return "UNKNOWN";
}
}
我们测试一下输出:
#include "gguf.h"
#include <exception>
#include <iostream>
int main() {
const std::string path = "qwen2.5-1.5b-instruct-fp16.gguf";
// const std::string path = "Qwen3.5-4B-BF16.gguf";
try {
const gguf_metadata meta = load_gguf_metadata(path);
print_gguf_metadata(meta);
} catch (const std::exception &ex) {
std::cerr << "error: " << ex.what() << std::endl;
return 1;
}
return 0;
}
正常输出:
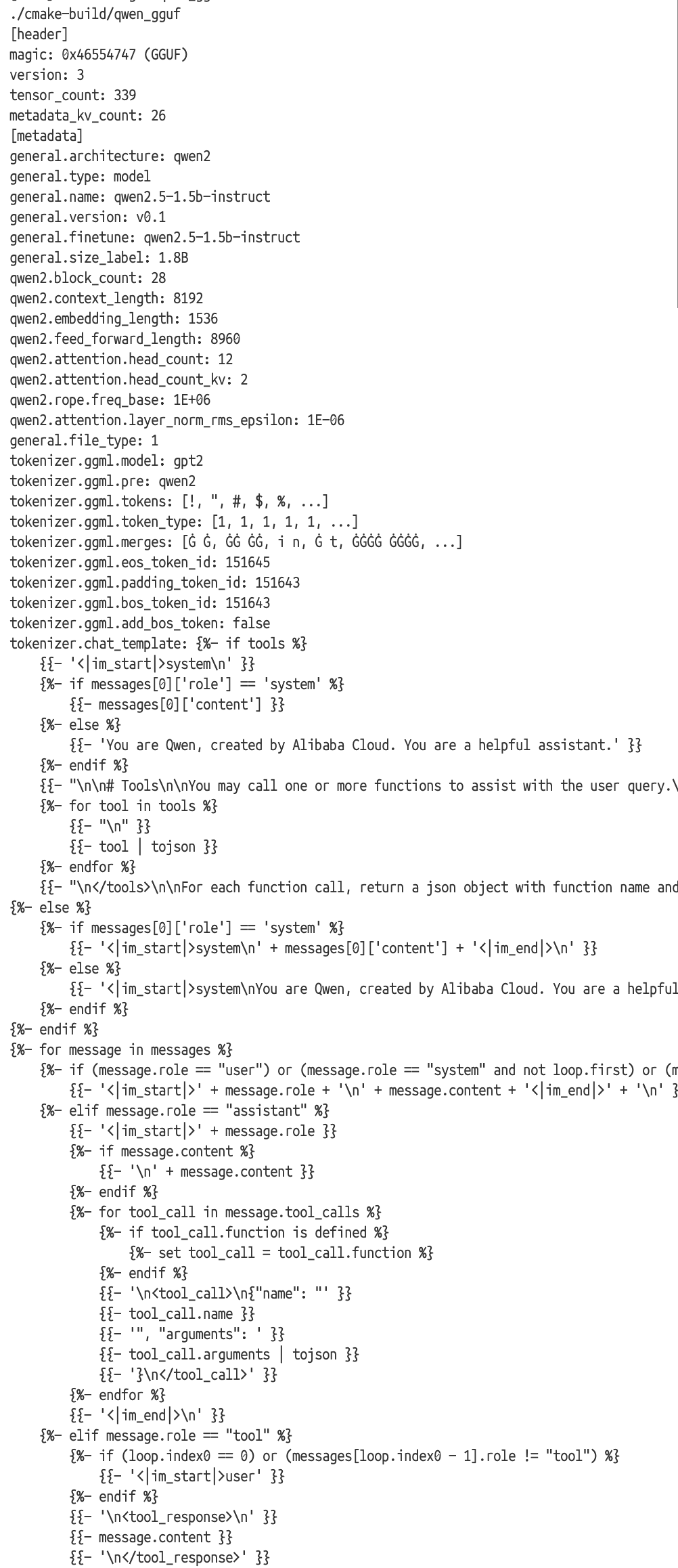
可以看到,我们成功读取到了gguf的metadata的信息,并且和huggingface上的数据一致。这样我们就可以在之后来使用这些数据了。
下面简单给一下这些metadata的意义:
基础信息
general.architecture: 模型架构名字,比如 qwen2
general.type: 文件类型,通常是 model
general.name: 模型名
general.version: 模型版本
general.finetune: 微调来源或微调后的名称
general.size_label: 参数规模标签,比如 1.8B
general.file_type: 权重量化/存储类型编号
general.quantization_version: GGUF 量化格式版本
模型结构参数 这些决定网络长什么样:
qwen2.block_count: Transformer block 层数
qwen2.context_length: 最大上下文长度
qwen2.embedding_length: hidden size / embedding 维度
qwen2.feed_forward_length: MLP 中间层维度
qwen2.attention.head_count: 注意力头数
qwen2.attention.head_count_kv: KV 头数,GQA/MQA 相关
qwen2.rope.freq_base: RoPE 的 base 频率
qwen2.attention.layer_norm_rms_epsilon: RMSNorm 的 epsilon
Tokenizer 信息 这些决定“文本怎么变成 token”:
tokenizer.ggml.model: tokenizer 类型,比如 gpt2
tokenizer.ggml.pre: 预分词/兼容方案,比如 qwen2
tokenizer.ggml.tokens: 词表,id 到 token 字符串的映射
tokenizer.ggml.token_type: 每个 token 的类型标记
tokenizer.ggml.merges: BPE merge 规则
tokenizer.ggml.bos_token_id: BOS token id
tokenizer.ggml.eos_token_id: EOS token id
tokenizer.ggml.padding_token_id: padding token id
tokenizer.ggml.add_bos_token: 编码时是否自动加 BOS
对话模板
tokenizer.chat_template: 聊天模板,定义 system/user/assistant/tool 消息如何拼成最终 prompt