.jpg)
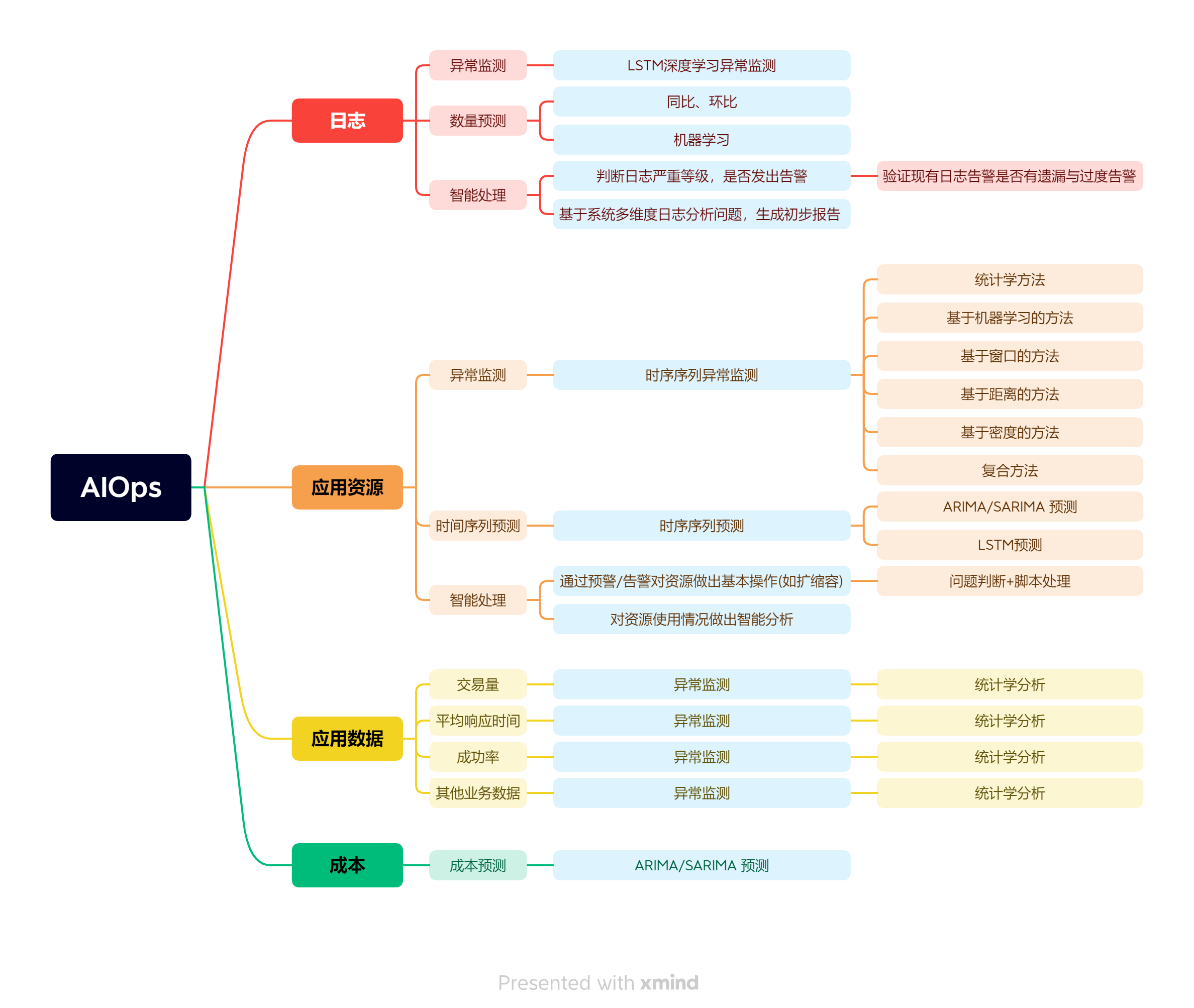
一、概述
在AI飞速发展的今天,智能化运维显得越来越重要;从传统的统计学分析出发,经由机器学习,再到深度学习,我们能利用的智能分析工具越来越多,下面便是尝试将AI智能体系引入传统运维的探索。
二、应用资源领域
1.概述
在这里,应用资源主要指的是运行项目的占用资源,例如基础的CPU使用率、内存使用量等,也可以扩展到线程数、文件打开描述符甚至网络带宽占用等等。
在应用资源领域,我们利用AI智能工具的主要方向有三个,分别是异常监测、数据预测与智能处理。
需要说明的是,此处的异常监测区别于传统的阈值告警类型的异常,我们可以通过算法来判断那些没有严格阈值指标的数据是否异常,或者对那些明显异常于往常数据量的值进行判断。
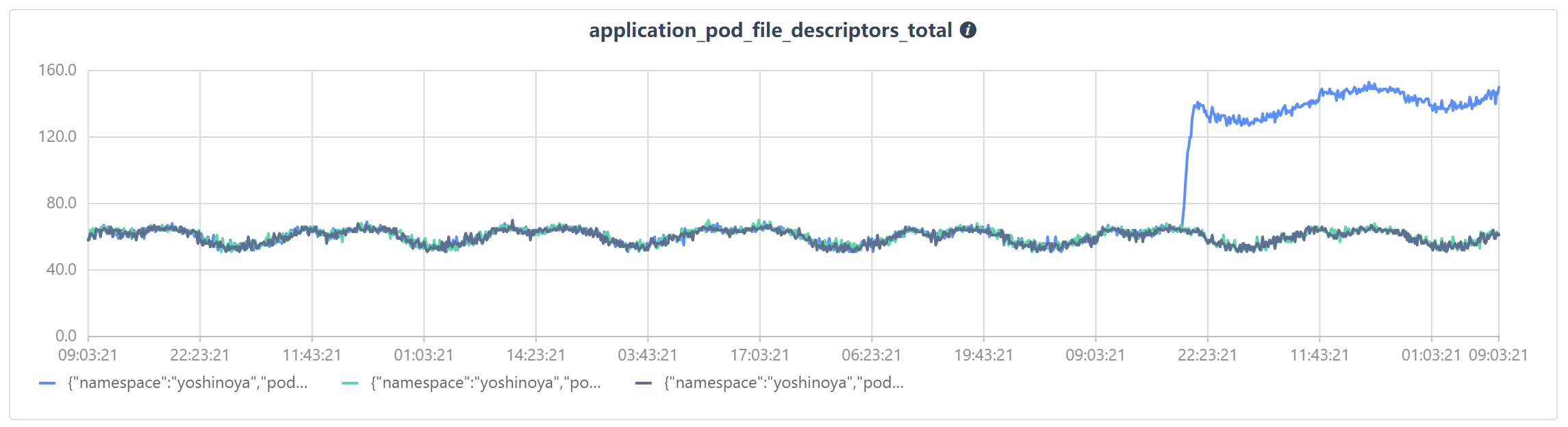
上面的图为一个应用的文件打开描述符的监控指标,可以清晰的看出在21点左右有一个明显的突增,后期经过排查为另一应用在容器中频繁调取其shell而没有释放的问题。但是该异常并没有通过告警暴露出来。
当然,这其中是必然有告警规则不充分的问题,但是如果真的要加入告警规则,则会面临另一个问题,那就是如何准确的给应用资源加上告警?
2.异常监测与时间序列预测
应用的资源数据实际上就是时间序列,而时间序列的异常监测与预测一直是学术界和工业界研究的热点和难点问题。在概述中给出的文件打开描述符数据,实际上就是一个标准的时间序列,其中x轴为持续增长的时间,y轴为该时刻对应的FileDescrptors数,这在Prometheus这种时序数据库是自然而然的东西。非常便于我们进行分析。
回到如何添加告警的问题上,我们如何判断一个时间序列是异常的?最简单的方式就是通过人去观察,对于人来说,可以通过图方便地看出离群点,并结合过往数据来判断是否确实是异常,还是普通的季节性波动,以及是否需要触发告警。而在告警工具中,最简单的告警规则是阈值类告警,当监测值大于或小于某个阈值时触发告警。但是这种方式显然过于简单粗暴:合理的阈值非常难界定,且针对季节性数据的判别有问题。
而如果想用更为智能的告警规则来判断,那么我们需要对离群点(outlier)进行判断,进而判断是否为异常点,需要注意的是,离群点不一定为异常点。而判断离群点的方法在下方:
统计学方法:这些方法是最常用的,包括自回归积分滑动平均模型 (ARIMA),季节性和趋势分解 (STL) 等。这些方法主要依赖于时间序列的统计属性,如均值,方差,季节性和趋势。
基于机器学习的方法:这类方法利用了各种机器学习技术,例如决策树、支持向量机、人工神经网络、深度学习等。其中,最近一些基于深度学习的方法(例如自编码器,长短期记忆网络)在时间序列异常检测方面表现出色。
基于窗口的方法:这些方法比较当前数据点和它的近邻(即窗口)。如果当前点显著地不同于其邻居,那么它就被认为是异常的。窗口的大小可以静态设置,也可以动态调整。
基于距离的方法:这些方法计算数据点之间的距离。如果一个点与其他点的距离超过了某个阈值,那么它就被认为是异常的。
基于密度的方法:这些方法依赖于数据点在特定区域内的分布密度。如果一个区域的密度显著低于其周围的区域,那么这个区域就可能包含异常。
复合方法:这些方法结合了以上的一种或多种方法,以提高异常检测的效果。例如,一种常见的方法是先使用机器学习模型训练数据,然后使用统计测试来识别可能的异常。
在这里我愿意将上述方法大致分为三类:
统计学类
数学模型类
机器学习(深度学习)类
首先来看统计学类,该类型为较为基础的判断,如同比、环比比较法,正态分布适用的3σ定律(3-sigma rule)以及类似的箱线图等,同理还有上面基于密度、窗口、距离的方法,这些方法简单来说都是通过一些数值计算来表征校验出问题的点 。
之后是数学模型类,该类型主要使用一些数学模型来对时间序列进行预测。如**ARIMA模型(Autoregressive Integrated Moving Average model,差分整合移动平均自回归模型)还有SARIMA模型(带有季节成分的ARIMA),**除此之外,还有Meta开源的Prophet时间序列预测工具、还有tsfresh、autots、darts与AtsPy等各种时间序列预测的库。通过进行时间序列的预测,可以进行后续的异常判断与检测。
最后是机器学习(深度学习)类,比较有效的方法为基于LSTM深层神经网络的时间序列预测,还有诸如xgboost和时间卷积网络等等。下面简单分析下季中方法的优缺点。
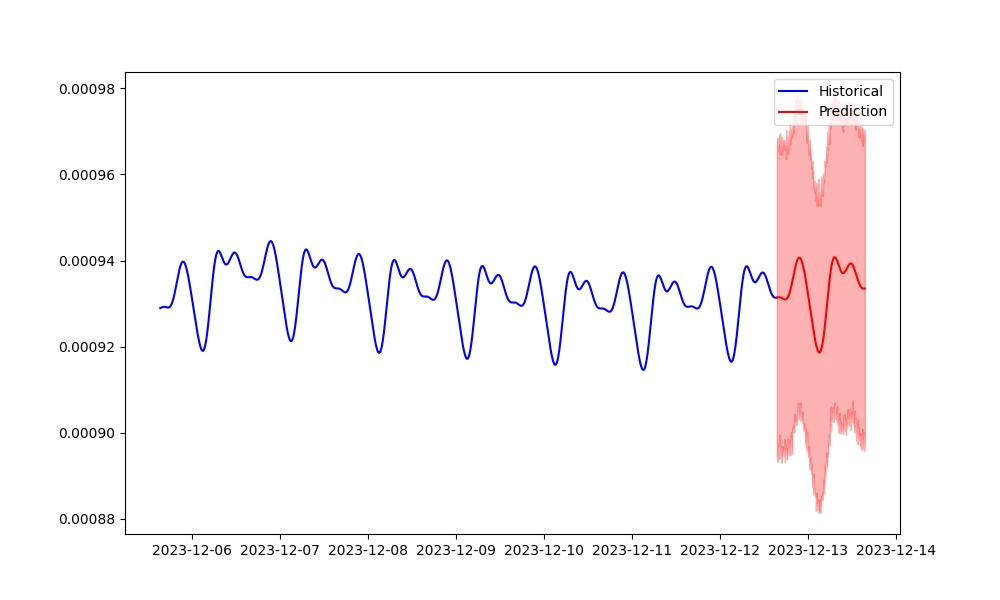
下面简单给出一个基于Prometheus采集的Pod CPU usage信息,并使用Meta的Prophet进行预测的代码和效果图