Computer Architecture 1 pipleline scheduling
Instruction Scheduling Techniques
Statically Scheduled Pipelines
Out-of-order Instruction Completion
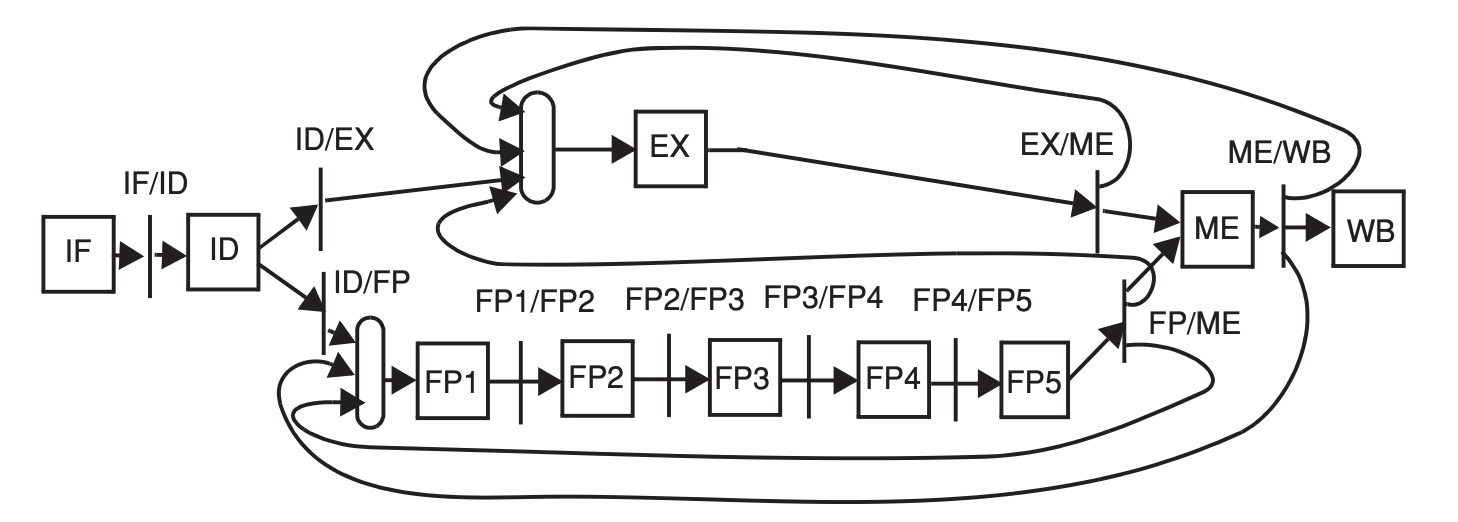
In the 5-stage pipeline all instructions start and complete their execution in process order because they all move through every stage of the pipeline in process order. Pipelines that take a variable number of cycles to execute different instructions may complete instruction execution out of process order.
Still in-order execution but out-of-order completion.
Structural Hazard

Two general techniques to avoid structural hazards
- Add hardware resources
- Deal with it by stalling instructions to serialize conflicts
Data Hazard

-
Data Hazards
In out-of-order processor, it is also three kinds of data hazards: RAW, WAR, WAW
Solution Method:
RAW: Tomasulo, Forwarding.
WAR: Register Renaming
WAW: Register Renaming, ROB(Reorder buffer)
-
Structural Hazards
It appears when more than one instructions compete for the same hardware resources.
Solution Method:
Reservation Stations, Issue Logic
-
Control Hazards
It cased by branch instruction, processor doesn't know next instruction.
Solution Method:
Branch Prediction, Speculative Execution, ROB, BTB
Superscalar CPU
Fetch, decode and execute up to 2 instructions per clock.
– Same clock rate as basic pipeline
– Easy (in this case) because of the 2 (INT and FP) register files
Static Instruction Scheduling
- Hardwired branch prediction
- Compile-time branch prediction
Compiler schedules instructions in code chunks:
- Local (basic block level)
- Global (across basic blocks):
- Cyclic (loops)
- Non-cyclic (traces)
-
Local Scheduling Example:

Local Scheduling:

Global Static Instruction Scheduling: Loop Unrolling
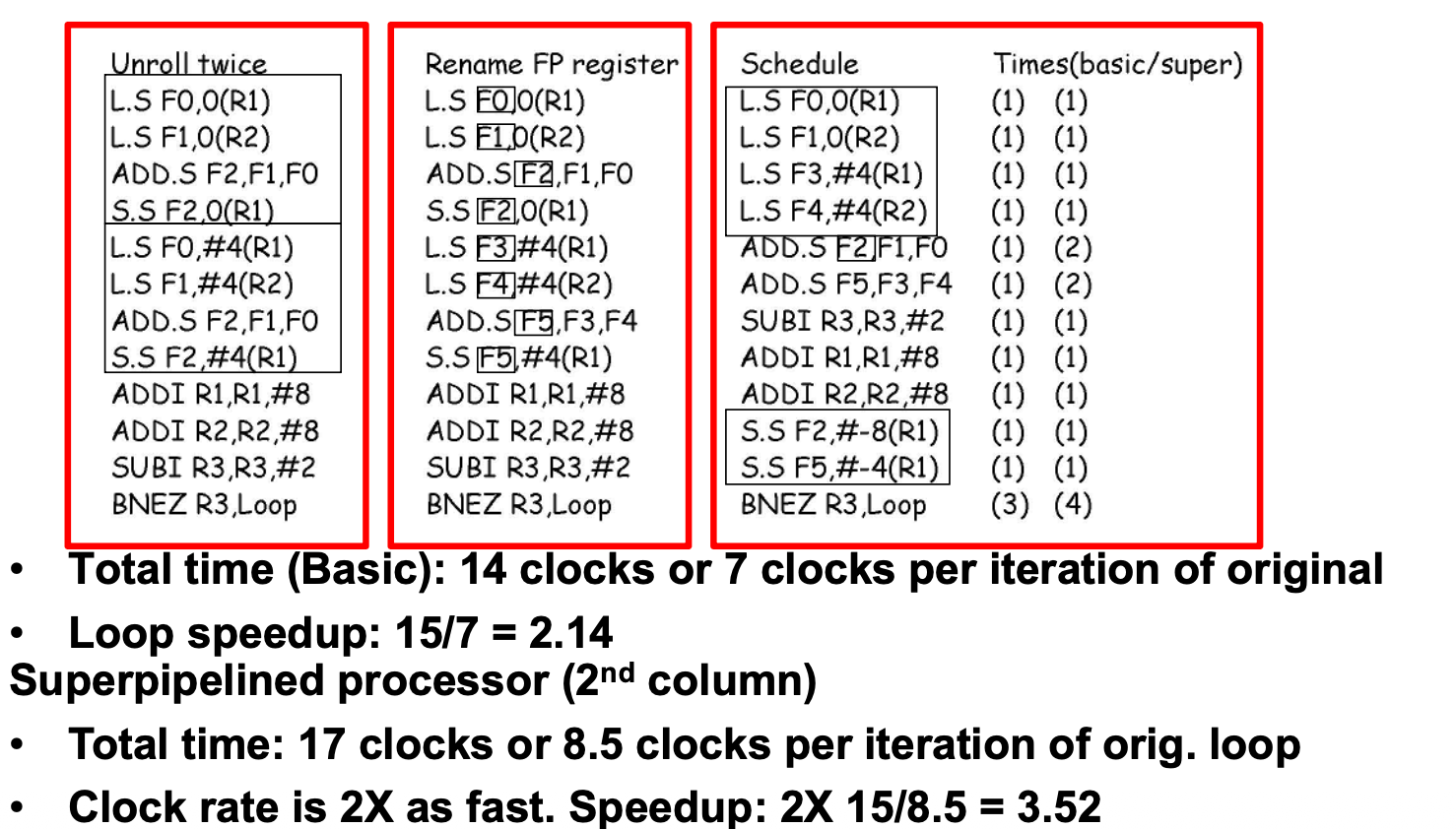
SpeedUp method: Unroll, Rename FP register, Schedule

Limitations of Loop Unrolling
Works well if loop iterations are independent
for (i=5;i<100;i++)
A[i]:= A[i-5] + B[i];
Loop-carried RAW dependency recurrence with distance 5 iter.
– Unroll loop 4 times
– 5 times => Loop carried dependency limits code motion
Consumes architectural registers for renaming
Code expansion
– Affects instruction cache (I-cache) and memory
Problem when the number of iterations is unknown at compile time.
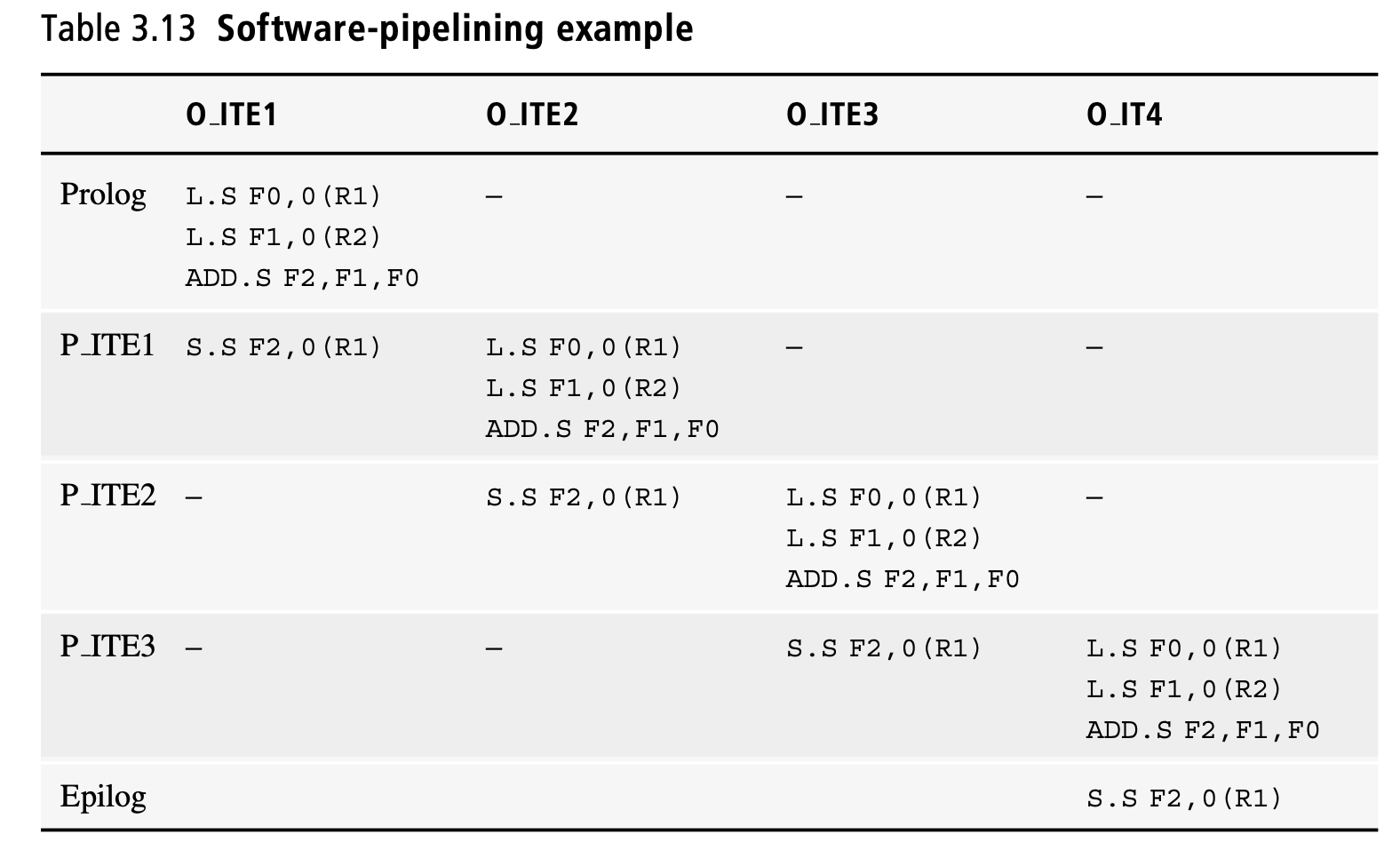
Software Pipeline
Original loop is translated into a pipelined loop
Pipelines dependent instructions in different iterations
Application to the simple loop:
Since the ADD.S is the long latency operation, we can pipeline the two Loads and the ADD.S with the Store
Dynamic Instruction Scheduling
Static pipelines can only exploit the parallelism exposed to it by the compiler
Instructions are stalled in ID until they are hazard-free and then are scheduled for execution
The compiler strives to limit the number of stalls in ID
However, compiler is limited in what it can do
Potentially there is a large amount of Instruction Level Parallelism (ILP) to exploit (across 100s of instructions)
Must cross basic block boundaries (10s of branches)
Data-flow order (dependencies) – not program order
Dynamic instruction scheduling
- Decode instructions then dispatch them in queues where they wait to be scheduled until input operands are available
- No stall at decode for data hazard – only structural hazards
To extract and exploit the vast amount of ILP we must meet several challenges
- All data hazards – RAW, WAW, and WAR – are now possible both on memory and registers and must be avoided
- Execute beyond conditional branches – speculative execution
- Enforce the precise exception model
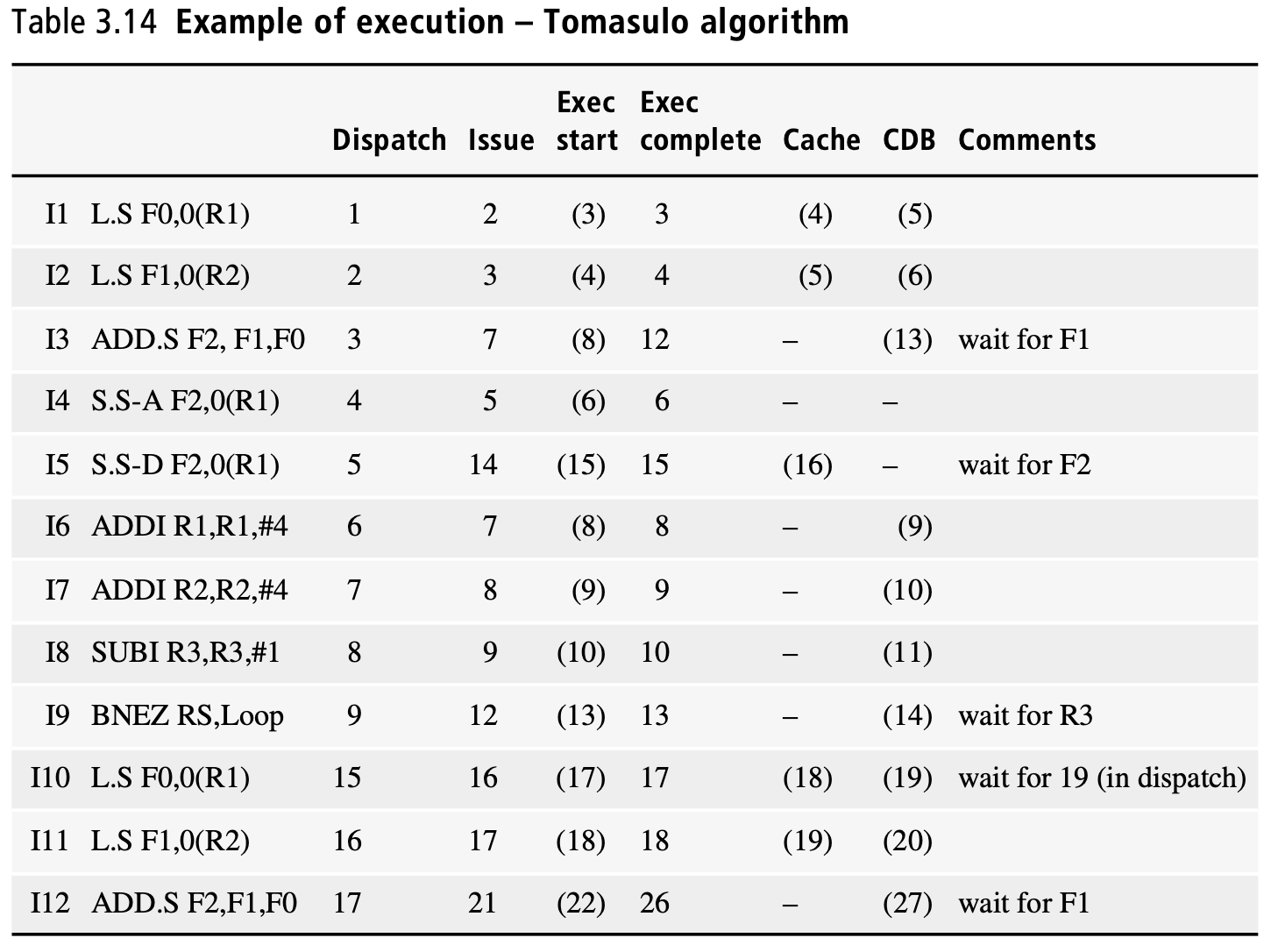
Tomasulo Algorithm
In static architectures an instruction does not start execution until it is free of all hazards with previous instructions in process order. Structural, data, and control hazards are all resolved in the ID stage. Once an instruction traverses the ID stage it will complete with no stall, unless and exception is triggered. As a result, static piplelines can only reap the performance improvements yielded by the instruction-level parallelism (ILP) present in basic blocks - of course, basic blocks can be enlarged by the compiler, especially in the case of loops.
To increase the ILP that can be exploited by the microarchitecture, instructions should be able to start their execution in any order that respects the dependencies implied by the program, but not necessarily in the process order.
So there are some basic requirements of such new pipelined architectures: 1. all data hazards must be solved: RAW, WAW and WAR data hazards are now pervasive, on both registers and memory operands. 2. control hazards must be solved: instructions must execute across conditional branches, otherwise ILP is limited by the size of basic blocks. 3.structural hazards must be solved: two instructions cannot reserve the same hardware resource in the same cycle. 4. the precise exception model must be enforced on some exceptions, as specified by the ISA.

In the front-end of the machine, instructions are fetched sequentially from the I-cache. They are then stored in a first in first out (FIFO) instruction fetch queue (IFQ). There are three issue queues, one for integer and branch instructions, one for loads and stores, and one for floating-point. Instructions wait in their issue queue until all their input register operands are available. The results of instructions are communicated to dispatched instructions waiting in issue queues through the common data bus(CDB).
When a register result is communicated on the CDB by an instruction, both the value and the tag of the destination register are put on the bus. The current tag on the CDB is matched against the tags of all operand entries in all the issue queues. The value on the CDB is written in all entries with a matching tag, and their contents are marked ready. Additionally, the register files are also accessed with register tags from the CDB. If the tag associated with a register matches the register tag on the CDB, then the value is written in the register and the register tag is set to invalid. Otherwise, if no register tag in the register file matches the tag of the register on the CDB, the value on the CDB is not written in the register file.
Branch predictor
1-bit predictor
The motivation behind the 1-bit predictor is to cover the conditional branches controlling the exit from a loop. Whether the branch is at the top or the bottom of the loop, its outcome is repeated during the entire loop, up until the last iteration, when the prediction inevitably fails. The 1-bit predictor fails twice per execution of a loop.
2-bit predictor
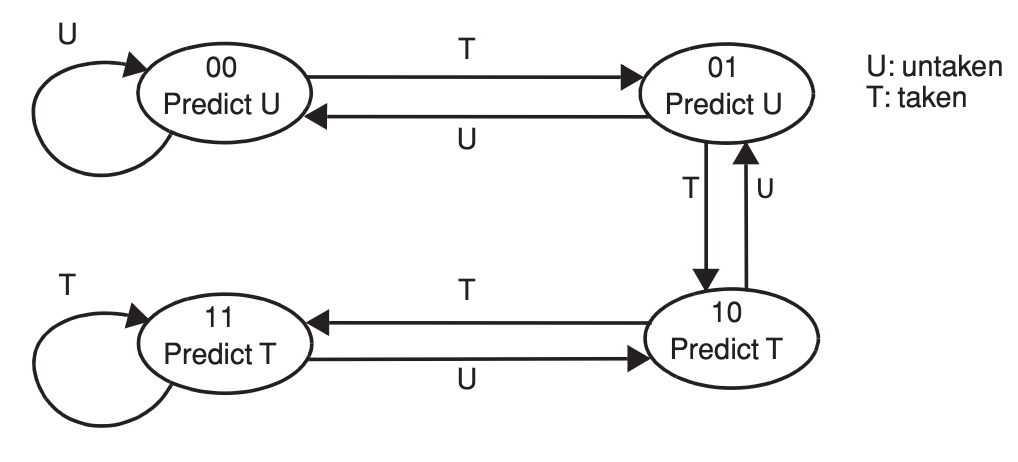
The 2-bit predictor improves the prediction rate on branches controlling loops. The basic idea is to change the prediction after two consecutive mispredictions rather than after every misprediction.
Two-level branch predictor
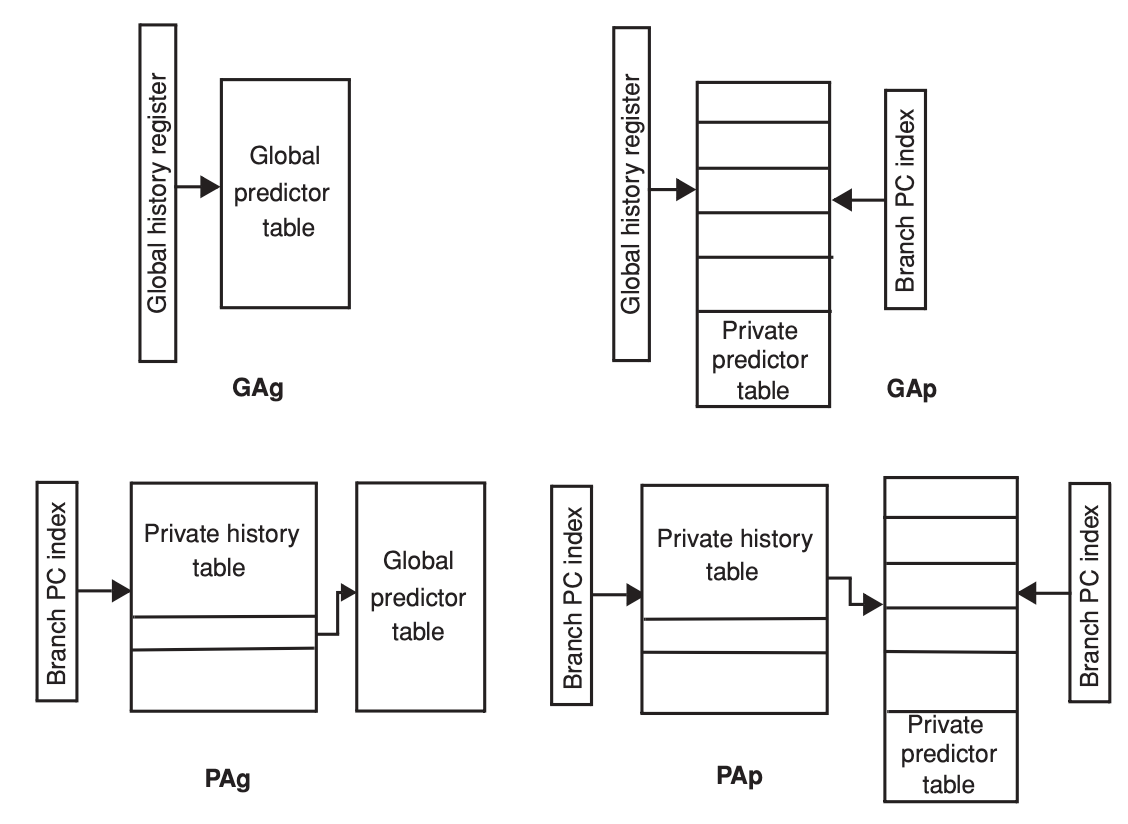
- GAg, global history table and global predictor table: histories and predictors are shared by all branches. Branches with the same global history interfere with each other and are predicted by the same bits.
- GAp, global history table and per-address predictor table: histories are shared by all branches but the predictors are specific to each branch. Branches have their own prediction bits, which are updated based on the global history.
- PAg, per-address history table and global predictor table: histories are tracked for each branch but the predictors are shared, so that all branches with the same per-address history share the same predictor and interfere with each other’s prediction.
- PAp, per-address history table and per-address predictor table: histories and predictors are private to each branch.
Adding speculation to the Tomasulo algorithm
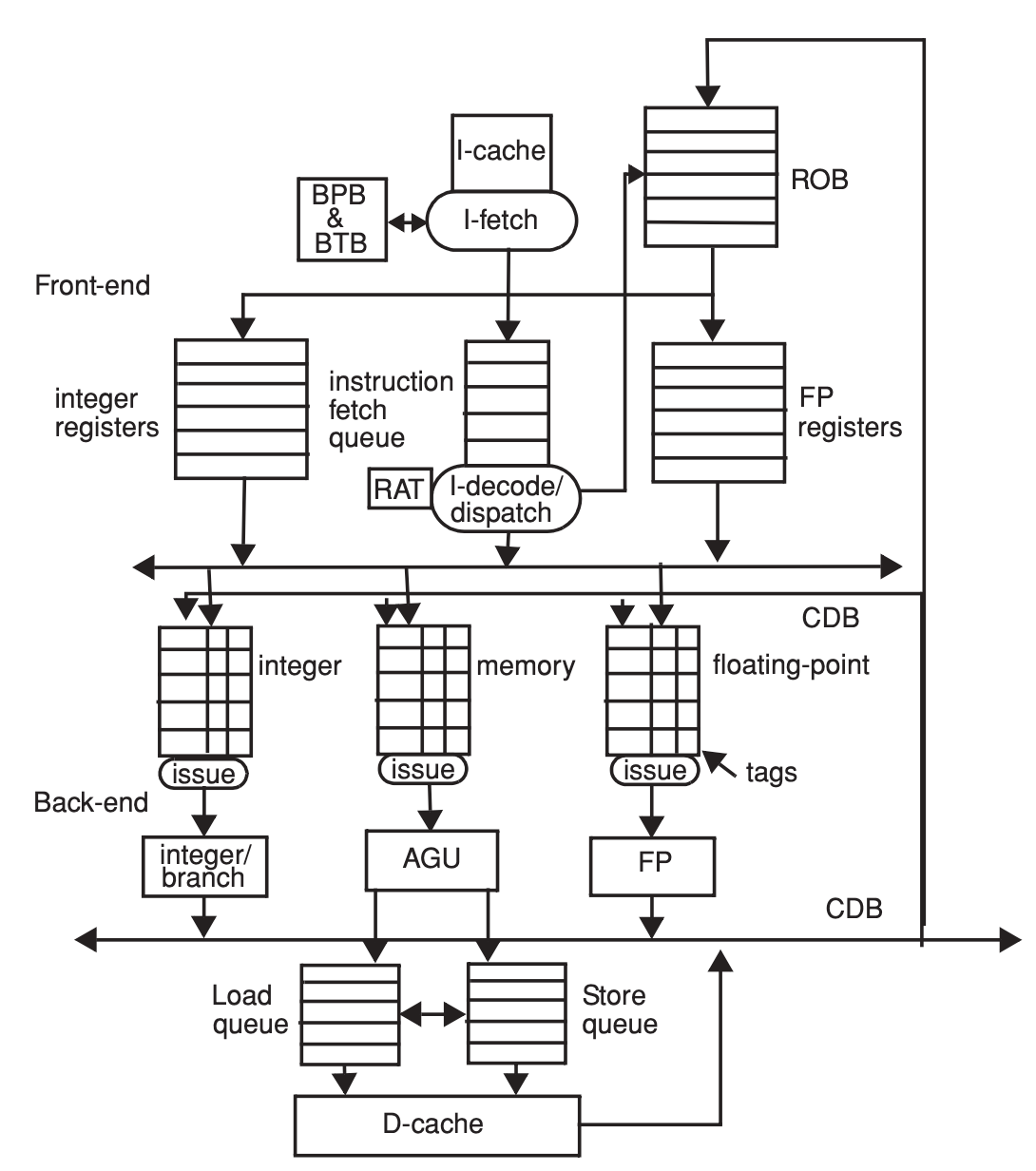
The units added to the previous, non-speculative architecture are the re-order-buffer (ROB), a branch target buffer (BTB) and a branch prediction buffer (BPB). The ROB is managed FIFO (first in fitst out) and has two functions:
- to keep track of the process order of dispatched instructions in order to help recover from mispredicted branches and precise exceptions;
- to serve as temporary storage for the registers, which are targets of speculative instructions.
The RAT is accessed with the architectural register number and each of its entry points to the location where the latest dispatched value is (either the tag of the latest instruction modifying it or a register number) plus one bit indicating whether the value is pending (not ready) in the back-end.
Instructions in the issue queues may start execution as soon as all their operands are available, as in the Tomasulo algorithm. When the execution is complete, the instruction writes its result on the CDB, the issue queue entries waiting on the result grab it, the result is written in the ROB entry, and the dispatch unit changes the status of the value in RAT to “available and speculative.” Note that the values are written directly in the ROB using the ROB entry number. Registers do not hold tags as in the Tomasulo algorithm. Registers are updated when an instruction reaches the top of the ROB.
RAT and ROB
Issue
RAT Role: Maps destination reg -> ROB entry
ROB Role: Allocates entry for instruction
Execute:
RAT Role: Tracks operand readiness
ROB Role: Stores results temporarily
Write-back:
RAT Role: Updates pending dependencies
ROB Role: Marks entry as completed
Commit:
RAT Role: Restores committed mapping
ROB Role: Writes results to register file
Instruction Status
Issued/Pending: Instruction issued, waiting for operands
Executing: Currently being processed by a functional unit
Completed: Execution done, result in ROB but not committed
Committed: Retired in order; result written to register/memory