

Tokenizer
概述
下一步是Tokenizer(分词器),Tokenizer是Embedding之前最重要的一步。
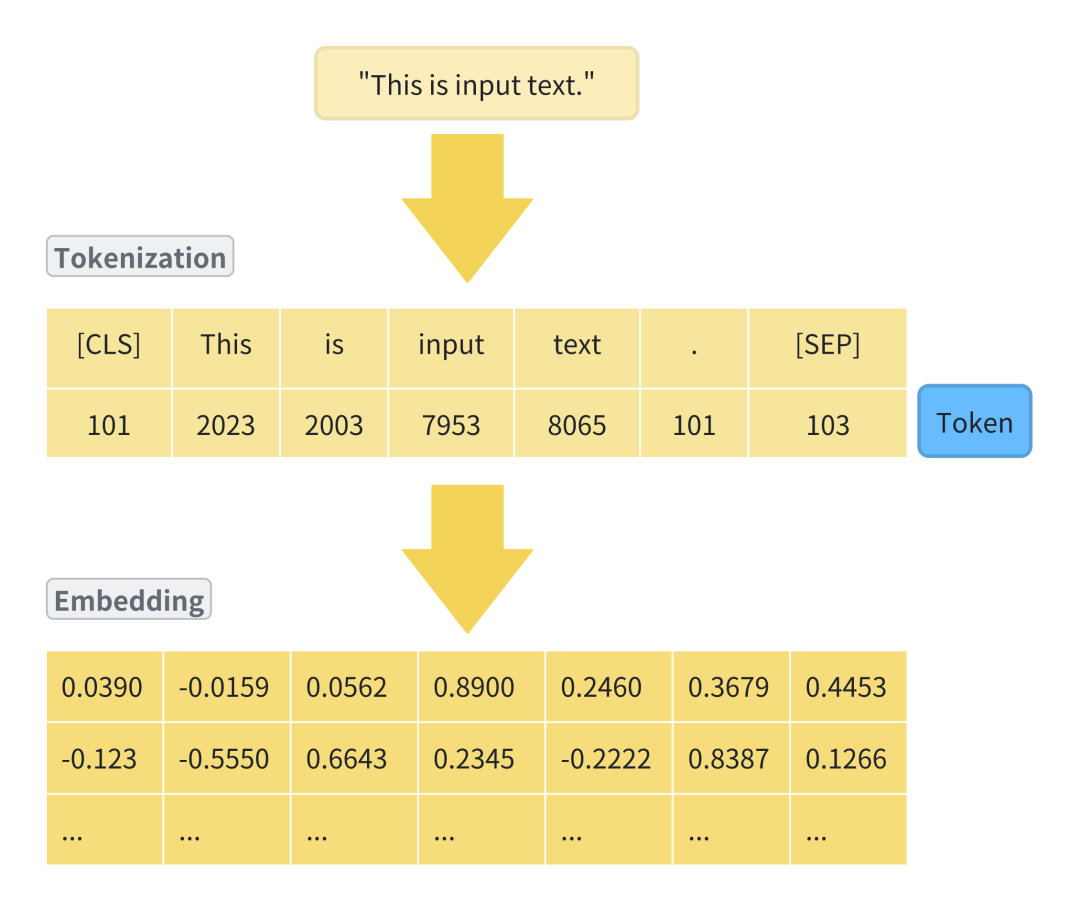
它是用来将本文拆分成模型或机器可以处理的小单位,并分配一个唯一的标识符(Token)。
分词流程
分词流程包括Normalization, Pre-tokenization, Model和Post-tokenization
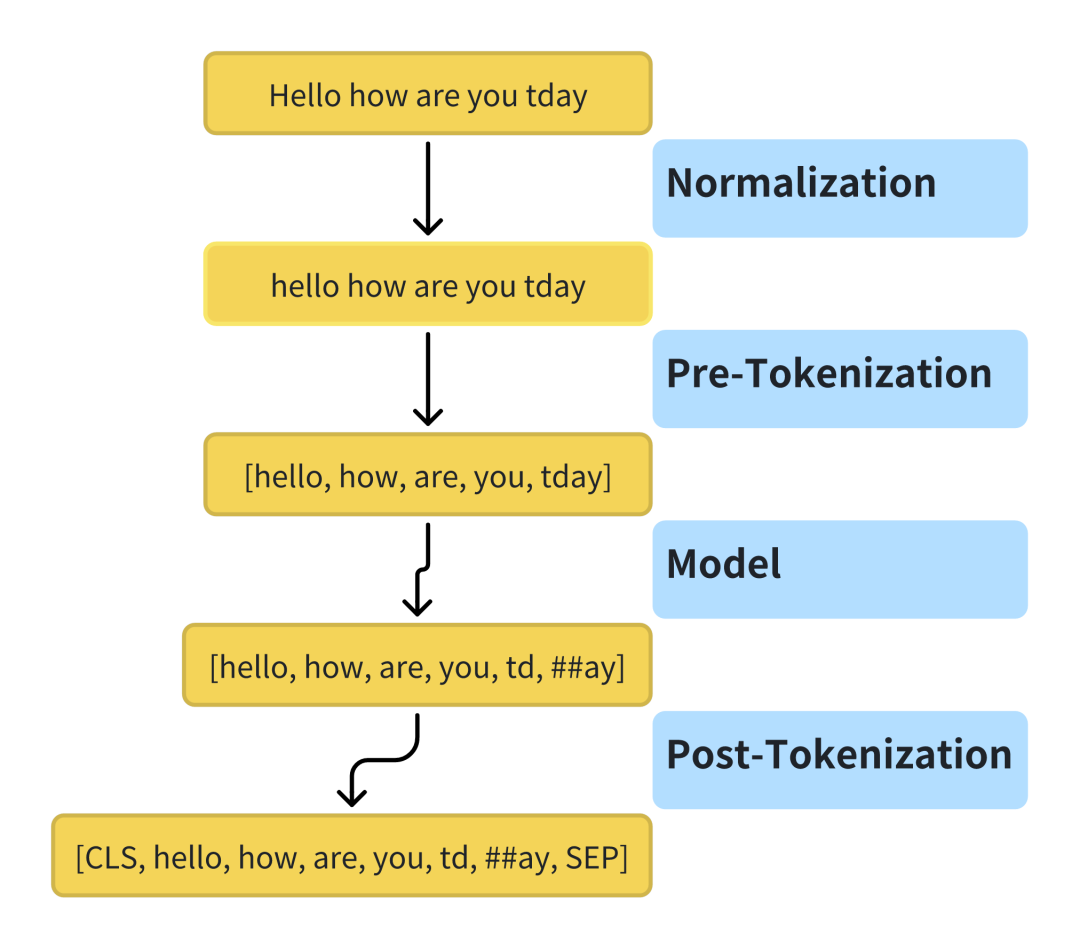
在这里,Model是分词的核心,在Pre-tokenization的基础上,根据选定的模型或算法(BPE,WordPiece, Unigram语言模型或者SentencePiece等)进行更细致的处理,包括通过大量文本数据,根据算法规则生成词汇表,然后根据词汇表,将文本拆分为Token。
其中,Qwen2.5使用的分词模型是BPE(Byte Pair Encoding),下面我们详细来看下BPE.
BPE
训练阶段
1.1 构建基本词汇表
BPE 训练的第一步是计算语料库中使用的唯一单词集,然后利用构成这些单词的所有符号来构建词汇表。(这里之所以没说字母是因为,除了字母以外还会有结束标记,或者其他Unicode字符)。
让我们举个简单的例子,假设我们的语料库只包含这五个单词:
"hug", "pug", "pun", "bun", "hugs"那么基本词汇表就是["b", "g", "h", "n", "p", "s", "u"]。在实际应用中,这个基本词汇表至少会包含所有 ASCII 字符,因为语料库中可能会有表情,因此可能还会有一些Unicode 字符。
BPE有一个问题:如果推理阶段,要被分词的文本中包含了训练语料库中没有的字符,该字符就会被转换为未知标记 (unknown token)。导致分析能力降低。
GPT-2/RoBERTa 的分词器有一个巧妙的解决方法:它们不是将单词视为 Unicode 字符的组合,而是将其视为字节的组合。这样一来,基本词汇表的大小就很小 (只有 256),但同时又能包含所有可能的字符,避免了未知标记的出现。这个技巧被称为Byte-level BPE。
1.2 词汇合并
在得到这个基本词汇表之后,我们通过合并 (merges)来不断添加新的词汇,压缩词汇表,直到词汇表大小到达阈值。这些合并规则会将现有词汇表中的两个元素合并成一个新元素。因此,在训练初期,这些合并主要是创建双字符的词汇,随着训练的进行,会逐渐形成更长的子词。
训练的每一步中,BPE 算法都会寻找现有词汇表中出现最频繁的一对标记 (这里的"一对"指的是单词中相邻的两个标记)。找到这个最频繁的标记对后,就将其合并,然后重复这个过程进行下一步。
让我们回到之前的例子,假设单词在语料库中的出现频率如下:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5) "hug"在语料库中出现了 10 次,"pug"5 次,"pun"12 次,"bun"4 次,"hugs"5 次。我们首先将每个单词拆分成单个字符 (这些字符构成了我们的初始词汇表),这样每个单词就变成了一个标记列表:
"h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5) 1.2.1 第一次合并
我们在单词上使用一个长度为2的滑动窗口,从而计算每个相邻字符对出现的次数。比如,字符对("h", "u")出现在单词"hug"和"hugs"中,在整个语料库中总共出现了 15 次。出现最多的字符对是("u", "g"),它出现在"hug"、"pug"和"hugs"这三个词中,在整个词汇表中总共出现了 20 次。
因此,分词器学习的第一个合并规则 (merge rule) 是("u", "g") -> "ug"。"ug"将被添加到词汇表中,并且在语料库的所有单词中,"u" 和 "g" 相邻出现时都会被合并成 "ug"。
在这个阶段结束时,词汇表 (vocabulary) 和语料库 (corpus) 变成了这样:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug"]
语料库: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)1.2.2 第二次合并
现在我们看到一些字符对可以生成长度超过两个字符的标记了。比如,字符对("h", "ug")在语料库中出现了 15 次。不过,在这个阶段出现最频繁的字符对其实是("u", "n"),它在语料库中出现了 16 次。
所以,第二个学到的合并规则是("u", "n") -> "un"。将 "un" 添加到词汇表并在语料库中进行合并后,我们得到:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
语料库: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)1.2.3 第三次合并
出现最频繁的字符对变成了("h", "ug"),所以我们学习到的下一个合并规则是("h", "ug") -> "hug"。得到了第一个三字母的标记。合并后,语料库变成了这样:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
语料库: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)我们会继续这个过程,直到词汇表达到预设的大小。
推理阶段
分词过程与训练过程密切相关。对新输入进行分词时,会按以下步骤进行:
标准化 (Normalization)
预分词 (Pre-tokenization)
将单词拆分成单个字符
按顺序应用学习到的合并规则到这些拆分结果上
让我们回顾一下训练时的例子,我们学到了三个合并规则:
("u", "g") -> "ug"
("u", "n") -> "un"
("h", "ug") -> "hug"用这些规则来分词,单词"bug"将被分解为["b", "ug"]。但是,"mug"会被分解为["[UNK]", "ug"],因为字母"m"不在基本词汇表中。这里的[UNK]表示未知标记 (unknown token)。同样,单词"thug"将被分解为["[UNK]", "hug"]:字母"t"不在基本词汇表中,而应用合并规则会先将"u"和"g"合并,然后再将"h"和"ug"合并。
BPE代码实现
这里首先是pre_tokenize函数。在这里,这个函数所做的工作就是normalization和pre-tokenization。因为Qwen 2.5模型是使用的GPT2的BPE token化处理方式。所以下面是这个pre-tokenie的的具体实现。
std::vector<std::string> Tokenizer::pre_tokenization(const std::string &text) const {
std::vector<std::string> pieces;
size_t i = 0;
while (i < text.size()) {
size_t leading_space_begin = i;
while (i < text.size() && text[i] == ' ') {
++i;
}
const bool has_leading_space = i > leading_space_begin;
const size_t leading_space_count = i - leading_space_begin;
if (i >= text.size()) {
if (leading_space_count > 0) {
pieces.push_back(text.substr(leading_space_begin, leading_space_count));
}
break;
}
const unsigned char ch = static_cast<unsigned char>(text[i]);
if (is_ascii_space(ch) && ch != ' ') {
size_t begin = i;
while (i < text.size() && is_ascii_space(static_cast<unsigned char>(text[i])) && text[i] != ' ') {
++i;
}
pieces.push_back(text.substr(begin, i - begin));
continue;
}
std::string contraction;
if (starts_with_contraction(text, i, contraction)) {
if (has_leading_space) {
contraction.insert(0, leading_space_count, ' ');
}
pieces.push_back(contraction);
i += contraction[0] == ' ' ? contraction.size() - leading_space_count : contraction.size();
continue;
}
if (is_word_like_byte(ch)) {
const size_t begin = i;
while (i < text.size() && is_word_like_byte(static_cast<unsigned char>(text[i]))) {
++i;
}
std::string piece = text.substr(begin, i - begin);
if (has_leading_space) {
piece.insert(0, leading_space_count, ' ');
}
pieces.push_back(std::move(piece));
continue;
}
if (is_number_like_byte(ch)) {
const size_t begin = i;
while (i < text.size() && is_number_like_byte(static_cast<unsigned char>(text[i]))) {
++i;
}
std::string piece = text.substr(begin, i - begin);
if (has_leading_space) {
piece.insert(0, leading_space_count, ' ');
}
pieces.push_back(std::move(piece));
continue;
}
size_t begin = i;
while (i < text.size()) {
const unsigned char current = static_cast<unsigned char>(text[i]);
if (current == ' ' || is_ascii_space(current) || is_word_like_byte(current) || is_number_like_byte(current)) {
break;
}
std::string ignored;
if (starts_with_contraction(text, i, ignored)) {
break;
}
++i;
}
std::string piece = text.substr(begin, i - begin);
if (has_leading_space) {
piece.insert(0, leading_space_count, ' ');
}
pieces.push_back(std::move(piece));
}
return pieces;
}然后是normalization,注意这里的normalization不是常见NLP里的文本规范化,而是把每个piece映射成byte-encoder字符串,下面是代码:
std::vector<std::string> Tokenizer::normalization(const std::vector<std::string> &pieces) const {
std::vector<std::string> normalized_pieces;
normalized_pieces.reserve(pieces.size());
for (const std::string &piece : pieces) {
normalized_pieces.push_back(normalize_bpe_piece(piece));
}
return normalized_pieces;
}
std::string normalize_bpe_piece(const std::string &input) {
static const std::array<std::string, 256> kByteEncoder = build_bpe_byte_encoder();
std::string normalized;
normalized.reserve(input.size() * 2);
for (const char ch : input) {
normalized += kByteEncoder[static_cast<unsigned char>(ch)];
}
return normalized;
}
std::array<std::string, 256> build_bpe_byte_encoder() {
std::array<std::string, 256> encoder{};
uint32_t extra_codepoint = 256;
for (size_t byte_value = 0; byte_value < encoder.size(); ++byte_value) {
const uint32_t codepoint =
should_preserve_bpe_byte(byte_value) ? static_cast<uint32_t>(byte_value) : extra_codepoint++;
append_utf8(encoder[byte_value], codepoint);
}
return encoder;
}之后是核心的model步骤,它对每个normalized piece拆成最小utf-8符号,按照merge_ranks反复找最佳相邻对,逐渐合并到不能再合并为止,最后把结果追加到总输出。
std::vector<std::string> Tokenizer::model(const std::vector<std::string> &pieces) const {
std::vector<std::string> model_pieces;
for (const std::string &piece : pieces) {
if (piece.empty()) {
continue;
}
std::vector<std::string> symbols = split_utf8_codepoints(piece);
if (symbols.size() < 2) {
model_pieces.insert(model_pieces.end(), symbols.begin(), symbols.end());
continue;
}
while (symbols.size() > 1) {
size_t best_pair_index = symbols.size();
uint32_t best_rank = std::numeric_limits<uint32_t>::max();
for (size_t i = 0; i + 1 < symbols.size(); ++i) {
const auto it = merge_ranks.find(merge_key(symbols[i], symbols[i + 1]));
if (it != merge_ranks.end() && it->second < best_rank) {
best_rank = it->second;
best_pair_index = i;
}
}
if (best_pair_index == symbols.size()) {
break;
}
symbols[best_pair_index] += symbols[best_pair_index + 1];
symbols.erase(symbols.begin() + static_cast<std::ptrdiff_t>(best_pair_index + 1));
}
model_pieces.insert(model_pieces.end(), symbols.begin(), symbols.end());
}
return model_pieces;
}最后则是post_tokenization,这里将处理好的model_pieces换为编码好的token.
std::vector<int32_t> Tokenizer::post_tokenization(const std::vector<std::string> &pieces) const {
std::vector<int32_t> token_ids;
if (add_bos_token && bos_token_id >= 0) {
token_ids.push_back(bos_token_id);
}
for (const std::string &piece : pieces) {
token_ids.push_back(require_token_id(piece));
}
return token_ids;
}